What goes into your scorecard?
Scorecards are a fundamental part of measuring performance and guiding activities and decision-making across an organization to drive business value. Your scorecard should tell a story and provide a framework for measuring your success.

The Jack of All Trades - What is it and do you need one?
In the ever-changing landscape that is IT, there is a growing pressure to diversify skills. While organizations and people have varying degrees of success with this, the reason for that pressure is clear: teams need to be able to cover more ground with...

IT - What's your passion? Passion drives us!
What inspired you to get into IT in the first place? Was it the creative medium in code development? Was it the challenge of having something broken and fixing that problem so that you can save somebody’s day? Can you connect your passion in your career...

We live in a world these days where copy & paste is the shortest path to winning. In a world of Stack...
Loop1 Answers Top Questions from Alert Noise Webinar
We recently hosted a webinar on alert noise – the...

When we started working with our client, he was overwhelmed.
He had finally convinced his organization...

Ding. Buzz. New email in inbox. Ding, Ding, DING! What’s that noise? Yes, it’s another alert, most...

Loop1 Systems is proud to be one of the selected SolarWinds partners to provide training for the SolarWinds...

Co-Owner William Fitzpatrick Buys Out Partner, Assumes 100% Ownership
AUSTIN, Texas (Dec. 6, 2017) –...

We’ve all been there. That same application admin has bonked his own server yet again. Only,...
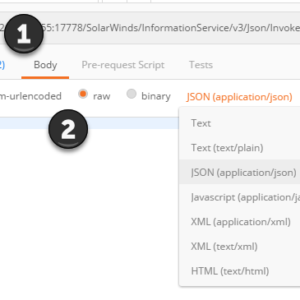
In the first post in this series, I started by going over authentication with the SolarWinds API and...

One of the things that is really great about Orion is that you can be up and running in under an hour...

Alerting Best Practices Once you have your software installed and a few nodes added to your inventory...