We Aren't Nuts... We Guarantee IT
"I guarantee it." Even today, years removed from when the ads first aired, when I hear that phrase, I still picture the owner & CEO of Men's Wearhouse talking about how you would "love the way you look" if you bought a suit from him--Learn about Loop1's...

Top 5 things to do as a new SolarWinds Administrator
In this latest blog post, from Loop1 programming guru, and training instructor, Steven Klassen, learn the top 5 things you may want to consider as a new SolarWinds administrator. You know there are probably some settings that should be given attention...

A Healthy Active Directory Makes for a Healthy Environment
October is National Cybersecurity Awareness Month! In honor of the occasion, hear from one of our Loop1 Technical Account Managers', about the importance of maintaining Active Directory (AD) and how a healthy AD can significantly improve your cybersecurity...


Part 2 of the series on the basics of setting up a network monitoring system.

It is surprisingly easy to set up any monitoring system in a way that causes a flood of red and green...

For the past 3 years and 7-ish months, I have been spending my days with Loop1 customizing the full range...
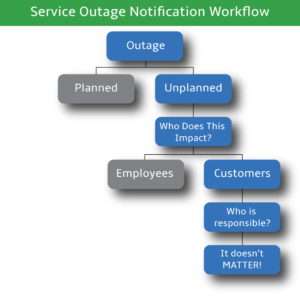
For service outage notifications, proper and effective communication to the customer is crucial. If you...

The most important part of your SolarWinds environment is the Database (and by extension the database...

Right on the heels of a very exciting NPM release (v11) comes an equally exciting update to the SolarWinds...
The latest version of Orion Network Performance Monitor (NPM) v11 dropped August 14th and in true SolarWinds...
CALLING ALL SOCCER FANS!!! Our Director of Technical Contract Services, Jason Henson, has put together...
SolarWinds recently released findings from a survey conducted amongst 118 Australian IT professionals...

Congratulations to Chrystal Taylor on becoming one of the newest MVP’s on the Solarwinds blog,...