
In today’s fast-paced IT landscape, the sheer volume of alerts generated by monitoring systems can be overwhelming. IT teams are often bombarded with thousands of notifications every day, making it challenging to distinguish critical issues from routine system behavior. Without a well-defined alert strategy, this constant stream of alerts can lead to ‘alert fatigue’—where important issues are overlooked or ignored due to notification overload.
So, what exactly is alerting, and why is it so important?
At its core, alerting is the process of a system taking action based on a predefined condition. This action usually comes in the form of a notification—whether via text, email, collaboration tools like Microsoft Teams, or ITSM platforms like ServiceNow or SolarWinds Service Desk. The goal of an effective alerting strategy is not just to notify your team but to provide actionable insights without overwhelming them. A carefully planned strategy ensures that alerts are meaningful and manageable and drive the right response.
When discussing alerting with a client, I usually discuss how all the following items affect the design and execution of alert configurations.
- Object Type
- Environment Topology
- Groups
- Dependencies
- Custom Properties
- Thresholds
- Custom or Out-Of-The-Box Alerts
- Alert Conditions and Actions
By carefully considering these elements, you can create a streamlined and effective alerting strategy that keeps your team informed without overwhelming them.
Object Type
The focus of an alert determines what specific aspect of your system is being monitored and why it matters. Is the alert targeting a node, interface, volume, application/component, or group? Understanding this focus is crucial because it helps ensure the right issues are being addressed. For example, alerts related to routing, CPU, memory, or hardware are all node-specific and require unique configurations. Defining the correct focus allows you to customize alerts effectively, ensuring that the right team can respond quickly to the specific issue being flagged.
Environment Topology
Why does topology impact alerting? It directly influences how groups and dependencies are defined. Everything relates to the path from the SolarWinds Orion poller to the node. By understanding this, you can implement cascading alert reduction, which identifies the upstream device that could affect one or more downstream nodes. If an upstream device fails, alerts can be reduced by acknowledging that the root cause affects other nodes behind it, rather than generating redundant alerts for each individual node. This ensures a more efficient alerting process and prevents unnecessary noise during outages.
Groups
Groups allow administrators to combine similar items, but in this case, the focus is on identifying whether an item is a parent or child, so they can be effectively used within dependencies. Parent groups represent the leading node or nodes in the path, while child groups represent the downstream nodes that depend on the parent. This setup allows for different relationship scenarios, such as one-to-one, one-to-many, or many-to-many, which helps in managing dependencies and ensuring efficient alerting.
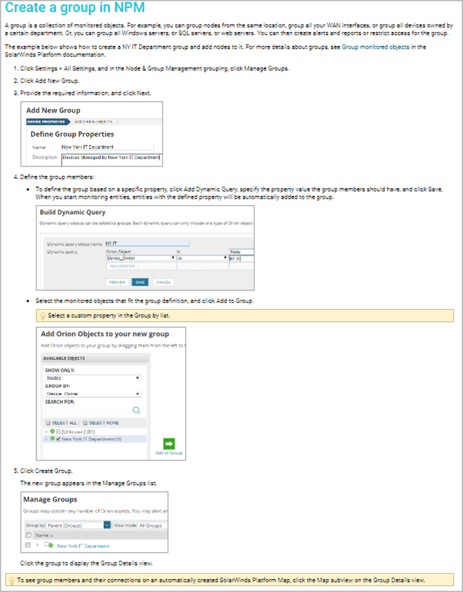
Dependencies
This process allows administrators to link nodes or groups together based on their parent/child relationship. The system evaluates these dependencies to determine whether a node should be classified as unreachable or down. Without dependencies, if an upstream device fails, alerts will be triggered for both that node and any downstream nodes. By defining dependencies, you can avoid unnecessary alerts for downstream nodes when the root cause is an upstream failure.
.png?width=600&height=547&name=Picture3%20(2).png)
Custom Properties
Custom properties are one of the most versatile components of the SolarWinds Orion Platform. They can be used to include or exclude certain objects from alerts, or to add data in alert actions, such as email notifications. One often overlooked function is the ability to use custom properties for dynamic email routing. For example, a custom property called “Alert_Email” can contain one or more email addresses or distribution groups, which automatically populate the “To” field in an email action. This is especially useful for routing tickets within systems like ServiceNow, SolarWinds Service Desk, or other ticketing platforms. The possibilities are endless, but proper planning is essential to make the most of custom properties for effective alerting.
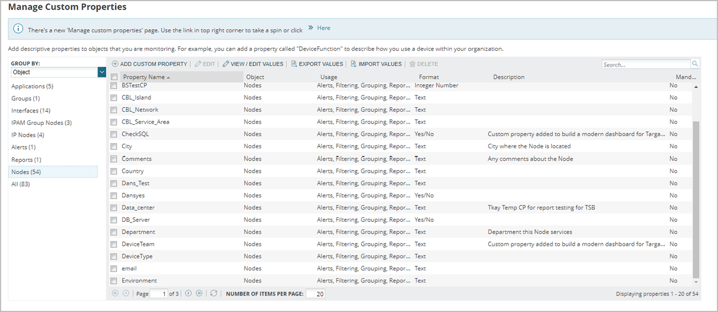
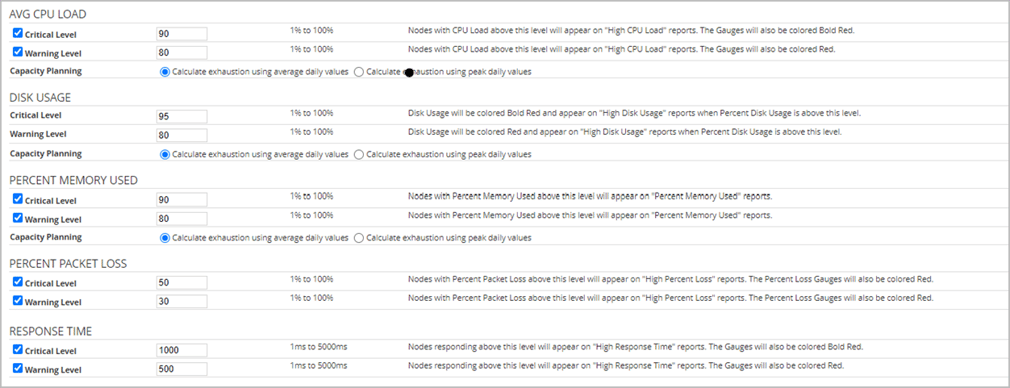
Thresholds
Thresholds are crucial when setting alerts based on conditions rather than fixed values, allowing for scalability across different objects. For example, critical CPU load levels may vary from node to node. Instead of creating multiple alerts for each specific value, you can define a dynamic threshold that triggers an alert when the “critical” condition is met. The alert then takes the appropriate action based on this condition. This approach reduces the overall number of alerts administrators need to configure and maintain, making the alerting process more efficient.
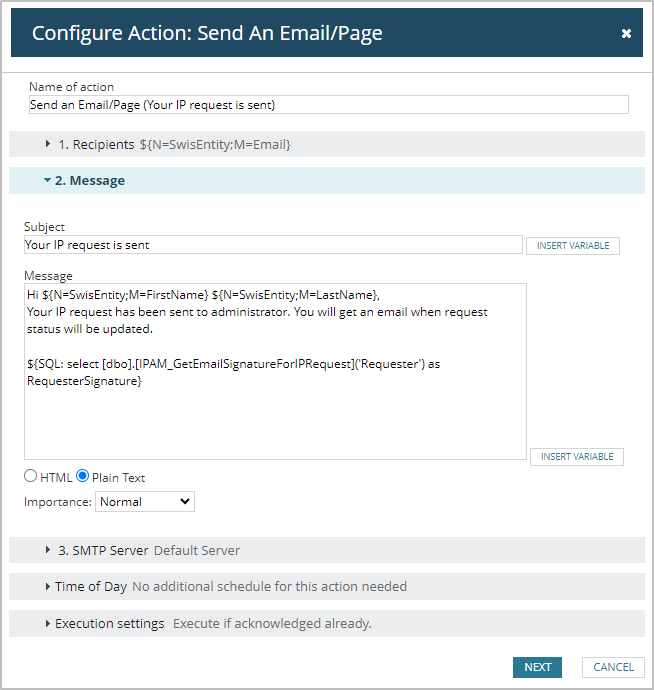
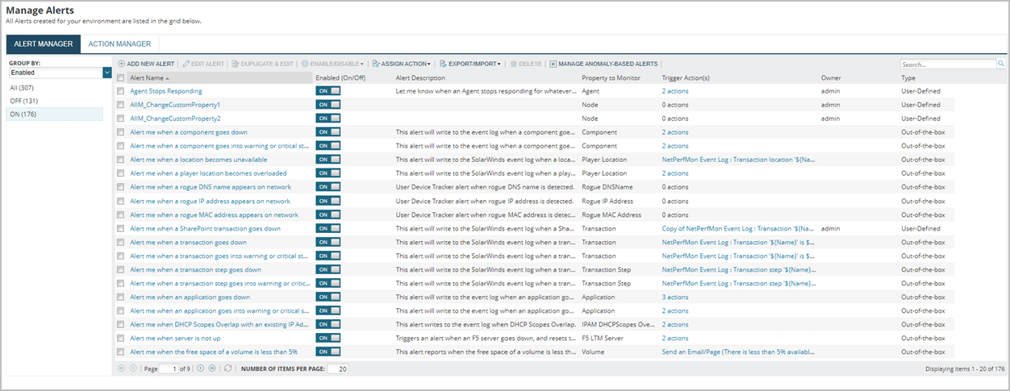
Custom or Out-Of-The-Box Alerts
When it comes to custom or out-of-the-box alerts, the question isn’t whether they should be used as-is, but how to tailor them to fit your organization’s unique environment and needs. While out-of-the-box alerts provide a good starting point for monitoring and can help you hit the ground running with a new installation, they are often too generic or overly sensitive for specific use cases. This can result in an overwhelming number of alerts that aren’t always actionable, leading to alert fatigue.
For any new installation or existing system in need of a revamp, I recommend disabling all out-of-the-box alerts and using them as a reference point. This gives you the flexibility to build custom alerts that better align with your infrastructure and priorities. By configuring alerts based on your organization’s specific requirements, you can ensure they are both meaningful and manageable.
In some extreme instances, we have been able to replace over 100 enabled and active alerts with as few as 10-20 more dynamic and functional-based alerts, streamlining the alerting process and reducing unnecessary noise.
The key takeaway is that out-of-the-box alerts should serve as a foundation, but to maximize efficiency and reduce unnecessary noise, they need to be tailored to fit the unique characteristics of your environment.
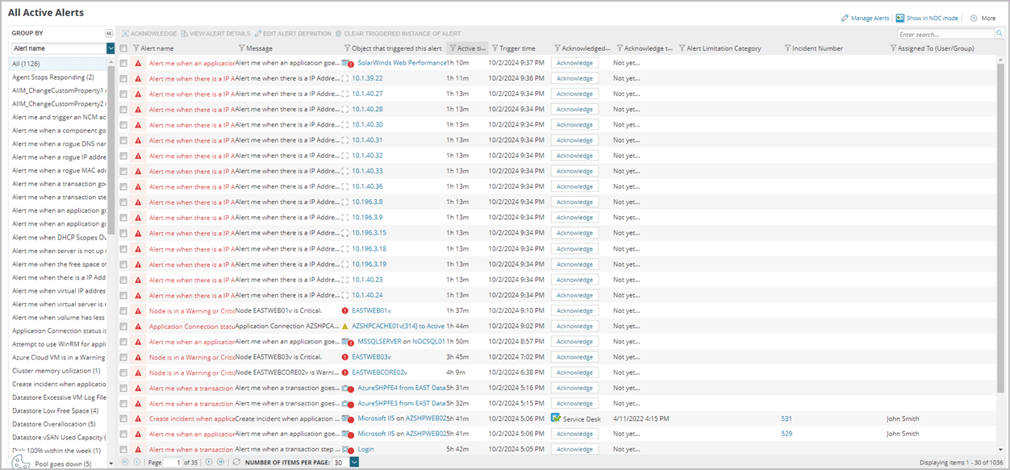
Alert Conditions and Actions: Keep it Simple, Stupid (KISS)—as simple as possible, only adding complexity when truly necessary
So, what does all this mean? It is simply following the old network saying, “Keep it simple, Stupid,” or the KISS rule. By keeping things simple yet flexible, everyone benefits. This approach reduces the effort needed to configure and maintain alerts by minimizing the number of active alerts, while also making each alert more versatile and resilient. It helps combat alert fatigue by preventing an overload of unnecessary notifications.
Each alert should be purposeful, with well-defined conditions and actions. Whenever possible, consolidate similar alerts where conditions and actions are the same, and only create separate alerts when there’s a clear difference. For example, you might have 24x7x365 alerting for production nodes, but only 8x5x5 alerting for non-production nodes.
CONCLUSION
In summary, building an effective alert strategy requires careful consideration of several factors—such as object type, environment topology, dependencies, and custom properties. By simplifying alert conditions and using dynamic thresholds, you can minimize the number of active alerts while ensuring each one is actionable and relevant. This approach not only reduces alert fatigue but also empowers IT teams to focus on what truly matters—resolving critical issues quickly and efficiently.
The “Keep It Simple” principle is essential when configuring alerts. By consolidating similar alerts and applying them strategically, your team can avoid being overwhelmed by notifications and stay focused on maintaining system health. Leveraging tools like custom properties and dynamic thresholds can further streamline your alerting process, making it more adaptable and resilient.
Looking forward, SolarWinds is ushering in the next generation of alerting with anomaly-based alerts. These advanced alerts learn what constitutes normal system behavior and trigger notifications only when something falls outside that baseline. By integrating artificial intelligence and machine learning, anomaly-based alerts help teams move from a reactive approach to a proactive one, identifying potential issues before they escalate. This evolution marks a significant shift in the monitoring landscape, allowing IT teams to stay ahead of the curve.
For more information on how anomaly-based alerts can enhance your monitoring strategy, visit SolarWinds Observability Self-Hosted Anomaly-Based Alerting.
And, if you need expert guidance on getting your alerting strategy under control, don’t hesitate to reach out to the team at Loop1!

Derik Pfeffer
Brings over two decades of experience in network engineering and enterprise technology to his role as Team Lead and Professional Services Engineer at Loop1. With a deep understanding of the SolarWinds suite, Derik has spent the last decade specializing in training and professional services, helping clients optimize their IT infrastructure. His career spans diverse roles, including Senior Sales Engineer, Technical Account Manager, and Global Field Engineering Manager. Derik is known for his hands-on approach to solving complex IT challenges and delivering tailored solutions to Loop1’s clients worldwide.