Alerting Best Practices
Once you have your software installed and a few nodes added to your inventory the next stop is going to be alerting. It’s great to have a dashboard with pretty green lights, but unless the system can let you know when something’s gone awry it won’t be very useful unless you’re looking at it when the issue arises.
There are out-of-the-box alert definitions ranging from the basic(node down) to the sophisticated (rogue MAC address appearing on the network). You can go through them and enable just the ones you want and leave the rest disabled. Some popular ones are the following:
- Node Down
- High CPU Consumption
- High Memory Consumption
- High Interface Traffic
- High Volume Consumption
Enabling any one of these is going, by default, to watch all of the nodes, interfaces, and volumes in your inventory for these conditions. If you’ve set up an email action, that email action is going to send a message to whomever you’ve chosen and usually that will be a distribution list of some kind with members that would be able to correct the issue that’s being alerted about.
Ordinarily that would be fine, but what if you have an Exchange administrator that only cares about the volumes (drives) on their Exchange servers? The configuration for that might look like this:
- Trigger Conditions
- Node Caption is like “Exch%”.
- Volume Consumption is greater than 80%.
- Reset Conditions
- Node Caption is like “Exch%”.
- Volume Consumption is less than or equal to 50%.
- Trigger Actions
- Write an outage entry to the NetPerfMon event log.
- Send an outage email to the Exchange administration team.
- Send an outage syslog entry to the local Splunk installation.
- Reset Actions
- Write a reset entry to the NetPerfMon event log.
- Send a reset email to the Exchange administration team.
- Send a reset syslog entry to the local Splunk installation.
That will work, but now you’ve done two things. First, you’ve doubled the number of alert emails that will go out for this particular issue when it involves an Exchange server (remember our original High Volume Consumption alert?).
Second, you’ve doubled the amount of work involved any time you need to change the configuration of your volume consumption alert. While this would work at the outset you can imagine that as you add one for your databases, another for your VoIP servers, and on and on things can get messy quickly.
Thankfully there is a better way.
When you’re building an alert, you can use variables in the message as you can see from looking at one of the defaults:
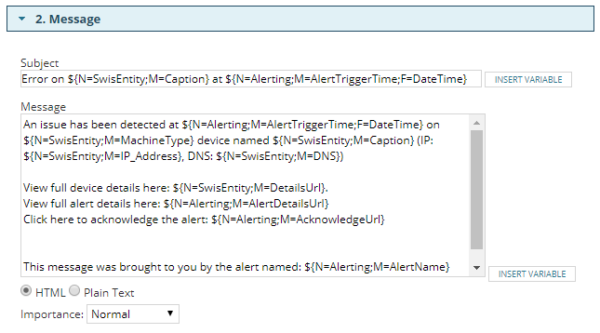
Each of the ${variable_name} bits represent some piece of information that’s being dynamically provided at the time that the alert triggers. That’s helped by having the “Insert Variable” button alongside each field that will let you choose from a list of variables to embed in your message.
The other place you can use variables is in the To/Cc/Bcc fields. It will use the default values from your the configuration under Settings > Configure Default Send Email Action so it’s not obvious immediately that it would accept variables.
Rather than creating an entirely separate alert we could just as well use a node custom property, let’s call it ContactEmail.
- Under Settings > Manage Custom Properties, click the ‘Add Custom Property’ button at the top of the interface.
- Choose ‘Nodes’ as the type custom property object type and click ‘Next’.
- Set the name to ‘ContactEmail’ (without spaces).
- Give it a description (e.g., “Additional email recipient for alerts on this node.”).
- Set the format to text.
- Do NOT check the box for “Value must be specified.”
- The reason for this is we may not necessarily have additional email addresses for the node in question. The Exchange servers, definitely, but if it’s just some device in your network that the regular distribution can handle you don’t want to force a value for each node.
- DO check the box for “Create a drop-down list of values…”
- Chances are you’re going to have a list of commonly-used alternate email distribution lists that would care about getting information about your node. Having a list prepared ahead of time (and admins can add to this list when they’re adding a node) is very helpful to avoid odd situations where it’s “address1@example.com, address2@example.com” for one node and “address2@example.com, address1@example.com” for another.
- Leave the usage checkboxes defaulted and click ‘Next’.
- You can use this interface to choose devices to bet set to the various values, but I typically skip it and use the Settings > Manage Custom Properties > View/Edit Values button because it has more of an Excel feel to it that’s familiar to most users.
Once all this work has been done, you can use your newly-created custom property in your alert definition’s Cc field. But where do we get the variable name?
For this, we can borrow the “Insert Variable” button in the message portion of the alert action. You can step through the process as if you were going to add your custom property to the subject of your email message by clicking the button alongside the dialog.
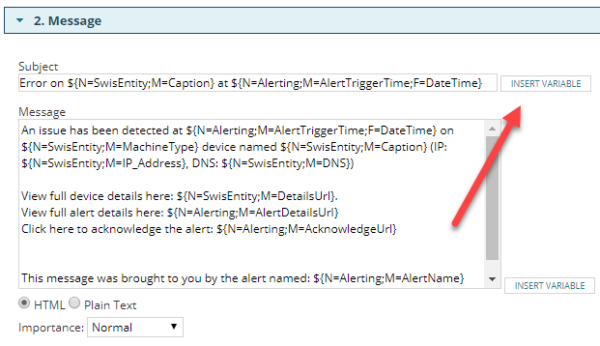
From here we can find our new node custom property:
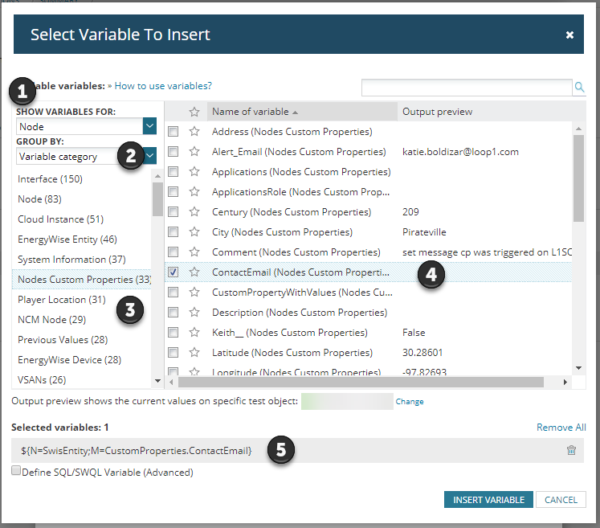
- Select “Node” as the variable type.
- Select “Variable category” to get the list of node variable categories.
- Select “Nodes Custom Properties” from the left dialog.
- Check the box next to “Contact Email (Nodes Custom Properties)”.
- Copy the resulting string at the bottom of the dialog.
With this variable in hand, you can return to your To/Cc/Bcc configuration and paste it right in:
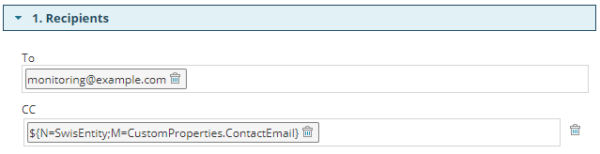
Now when this generic alert triggers the monitoring team will get their email as they always did but whatever email addresses (comma or semicolon delimited) in the ContactEmail custom property for the node will also be used.
This nets us less configuration to keep track of and that’s a good thing. Go forth and conquer!
Steven Klassen
Field Systems Engineer








